
© Agency for Cultural Affairs.
坂本 のどか
写真:栗原 論
マンガ・アニメーション・ゲーム・メディアアートの作品情報や所蔵情報の整備と、メディア芸術へのアクセスおよびその保存・利活用の要となるデータの提供を目的に、文化庁により構築・運営されてきた「メディア芸術データベース」(以下、MADB)。本データベースは、2015年3月に開発版が、2019年11月にベータ版がリリースされました。その後2023年4月、MADBに関する事業は文化庁から独立行政法人国立美術館国立アートリサーチセンターに引き継がれることとなり、2024年1月31日、名称から「ベータ版」が取れ、正式にリリースされました。その約1カ月後に行われた本対談では、MADBの設計に携わるお二方、大向一輝氏と三原鉄也氏を迎え、ベータ版からの進化や、この4年における世の中の変化とMADBの関係など、さまざまにお話しいただきました。

大向 2019年のインタビューでもお話ししましたが、MADBで特に大事にしているのは、長い時間を経ても情報が消えないことです。いま誰もが知っている作品でも、いつか忘れ去られてしまうこともある。作品が存在した記録をできる限り長くとどめておくために、僕たちがやっている最も重要な作業は、作品の一つひとつに未来永劫変わらないIDをつけることです。いつ誰がそのIDを呼び出しても、同じ結果、同じ作品の情報が返ってくる。それを実現し、継続可能にするためのデータやシステムの設計、運営体制づくりをしています。
三原 加えて、いろいろなところからデータを集めていることもMADBの特徴です。そうしないとメディア芸術のデータベースはつくれない。メディア芸術にはマンガ、アニメーション、ゲームなどのエンターテインメント、メディアアートとさまざまなものが含まれるからです。加えて、マンガ一つとっても、雑誌や単行本、電子書籍など多様な形態を持ち、また原画などの関連資料も存在します。さらに新しいものがどんどん生まれてくるのもメディア芸術です。
また、メディア芸術が自らメディア芸術を名乗っているとは限りません。ゲームであれば家庭用ゲーム機やデジタルゲームはメディア芸術として想像しやすいですが、ならばゲームセンターにあるようなエレメカや昔のピンボール、ボードゲームなんかは対象になるのか。議論してもすぐに決められないような対象も多い。範囲を見定めるためにも、すでにメディア芸術と見なすことのできる対象のデータや資料を持っている機関と連携してデータをつくる必然性があるわけです。世の中には流通など、業務のために使われているデータというのは実はあちこちにありますし、個人レベルのコレクターや研究者がデータをつくっている場合もあります。それらをつなげてマッシュアップして、メディア芸術の作品情報として整理をするというのが、私たちの仕事であり価値だと思っています。

大向 2019年11月のベータ版リリース以降、メディア芸術を保存する動きは博物館や美術館、図書館など、さまざまなところで高まっています。また2022年には博物館法が改正され、資料のデジタルアーカイブ化が努力義務になりました。その影響は大きく、データをつくり提供するのは必要なことなのだという意識が定着してきています。
「MADBとデータを連携させたい」「データを活用したい」という相談も年々増えてきています。連携によって、これまでリーチが難しかった過去の資料、例えば国立国会図書館にも納められていないような1950年代の古いマンガを扱っている機関のデータが新たに登録され、希少資料のカバレッジが上がるといったことが起きています。当初のイメージとしてあった、多機関との連携を前提としたデータベースの姿が見え始めていると感じます。
一方、連携のパートナーはそれぞれに目的を持って、それに見合ったデータをつくられているので、MADBにそのまま入れ込こんでも統一的に扱うことはできません。どう整理すれば連携できるかを考える必要があります。
また、いろいろなところと連携するMADBだからこそ見えるものもあります。あちらとそちらで実は同じ課題に直面していらっしゃる、といった発見もあります。
三原 連携先の現場を見に行くことも僕の仕事の一つなのですが、おっしゃる通りで、資料としては同じものを扱っていても、バックグラウンドや目的が違うとそれぞれつくるデータが違います。
例えば同じ本でも、図書館と博物館、大学図書館と市立図書館では、タイトルや目次の取り方すら違うこともあります。それは本をどう管理するか、誰が探しやすいかなど、さまざまな要因が関係しています。理由を探ると面白いのですが、連携のために受け取るデータとしては悩ましい。
でもそうしていろいろなところのデータを見ることで、「なぜ違うのか」がある程度説明できるようになるのです。そうすると「じゃあ今回の目的のためにはこのやり方がいいね」という話ができるようになる。連携するためにはそれがとても大事です。

三原 他機関のデータをMADBに取り込めると、一気に情報量を増やせるので非常にありがたい。その反面出てきている悩みというか、うれしい悲鳴もあります。例えばアニメの再放送です。再放送で次世代に爆発的に人気ができる作品などもあり、再放送は作品の歴史を知るうえで重要なデータだと考えていますが、いざ再放送のデータを取り込もうとすると、アニメチャンネルでの再放送は新しい作品の放映よりもずっと膨大で、アニメ分野のデータの全体量に対して、再放送の情報がとても多くなってしまうのです。
再放送された同じ作品のデータをまとめて扱えるように紐づけておけば良いのですが、データ整備の実作業や効率のよいデータ整備作業のための技術開発を進めていく必要があります。
大向 マンガ分野では愛蔵版や廉価版にも共通する悩みですね。それらも作品の流通の一部ですから取り込む必要はあるわけですが、どんな仕組みのなかで扱うべきなのか。たまたま見かけたから入れるというわけにはいきませんからね。
三原 データがあること自体はいいことなのですが、どう調和させていくかが難しいところです。
これまで、MADBでデータをつなげることを一生懸命考えてきたわけですが、別のレイヤーで見ると、それはデータを扱う仕事や人をつなげることでもあると思うようになりました。結局、アーカイブをマネジメントしたり利用したりする人をつなげないとデータベースは機能しない。そういう意味では、データベースだけではなく、担い手をつなげていくプロジェクトでもあるのです。
大向 MADB開発の歴史を振り返ると、一覧を見ることも検索もできなかった時代から、キーワードを入力すると何かがヒットするようになり、そこからさらに、4分野を統合的に検索できるようデータを整える段階がありました。ここまでがベータ版で一旦達成されたところですね。
三原 これは私の捉え方ですが、データを整えるというのは、情報の粒度を揃えるチャレンジだったと思っています。
例えばマンガでいう「単行本」は、アニメーションなら、ゲームなら何にあたるのか。分野によって情報の粒度はさまざまです。アニメ同士なら整合性が取れているけれど、マンガと並べるとなんだかズレてしまうといったことが起こらないように、適切な粒度を規定してつくったのがベータ版です。粒度を揃えることで横断的に検索が可能になり、統合的に扱えるデータになったわけです。
大向 そうですね。これまでずっと「理想的なデータはどうあるべきか」という議論を続けてきました。一般的に、情報システムをつくる場合に考えるのは、現場でつくられているデータと、システムを動かすのに最適化されたデータの仕様です。そのどちらでもない、メディア芸術自体を表現するためのデータのあり方を追求したのです。まずは、ベータ版をリリースした少し後に、その「理想的なデータ」をデータセットの形で公開・配布しました。まだそれを載せられるシステムにはなっていないけれど、一旦配ってしまおうと。ただ、それは単なるデータの塊でしかなく、自分でプログラムを組んで処理できる方にしか扱えませんでした。
その後、少し勉強すれば比較的簡単にデータにアクセスできるように、MADBを活用するためのサイト「メディア芸術データベース・ラボ(MADB Lab)」内でSPARQLクエリサービスを立ち上げました。ブラウザ上でクエリと呼ばれる命令文を書くことで、MADBに登録されているデータを複雑な条件で検索し、抽出することができます。
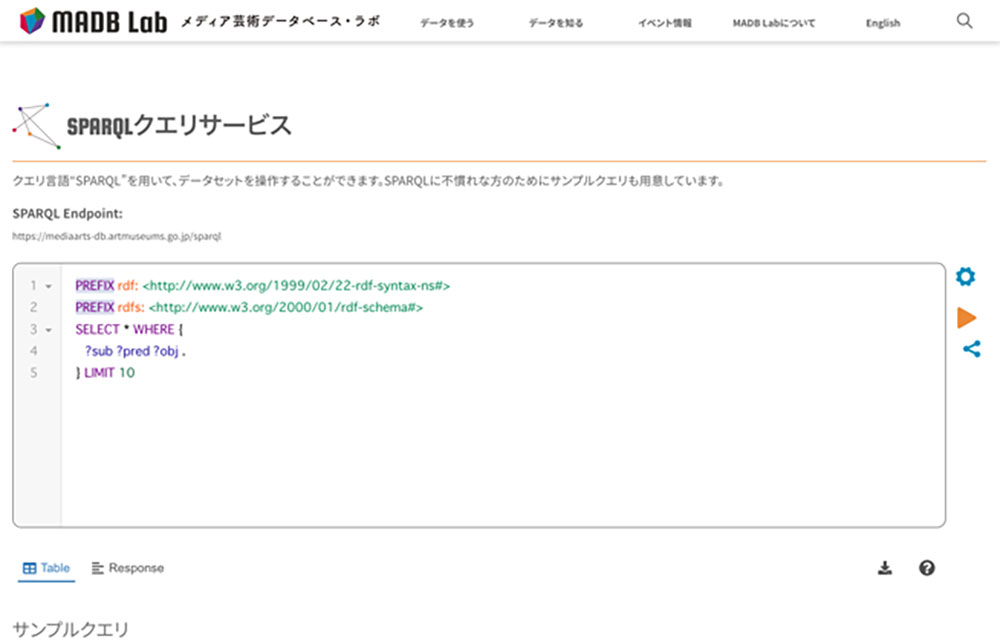
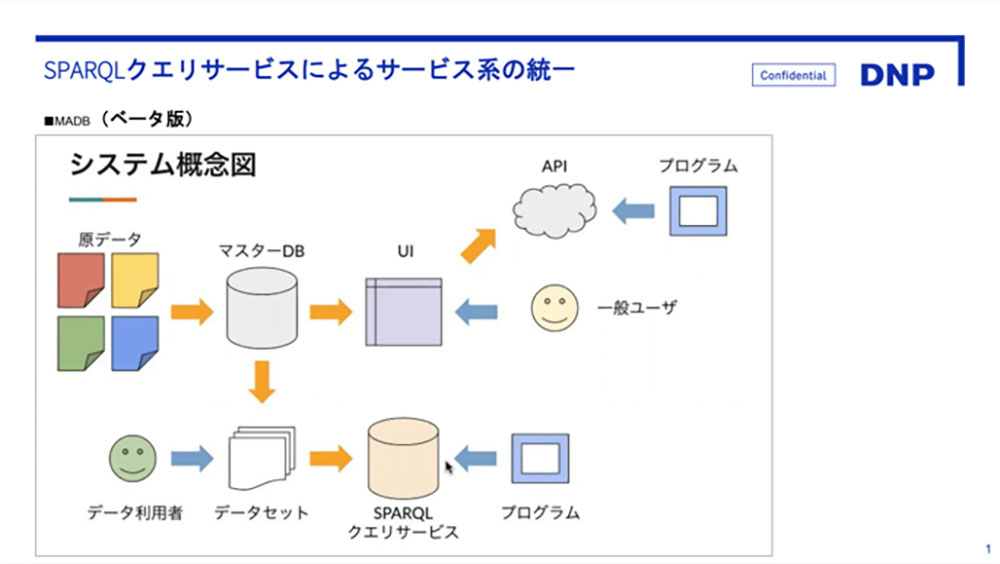
大向 MADBのインターフェイス上にはシンプルなキーワード検索機能や詳細検索での絞り込み機能だけがあり、複雑な検索はSPARQLクエリサービスで、という役割分担になっています。高度な検索ができないとデータのポテンシャルが発揮できないし、ユーザーのさまざまな発想も受け止められない。一方でどんなインターフェイスをつくればいいのか、正直我々も想像できなかったのです。
SPARQLクエリサービス自体はこれまでにもあったので、ユーザーから見ると大きな変化はないのですが、ベータ版ではMADB本体とクエリサービスのシステムが分かれていて、新たなデータが登録されるたびに両方をアップデートしなければならず、コストや今後の継続の面で課題が生じていました。正式版公開にあたり、それらの基盤となるシステムを一つに統合しました。キーワード検索で素早くデータを閲覧できるMADBと、より深くデータを追いかけるSPARQLクエリサービスを一つのシステムで回せるようになった。外から見ても実感できることではないのですが、これは結構な大工事でした。
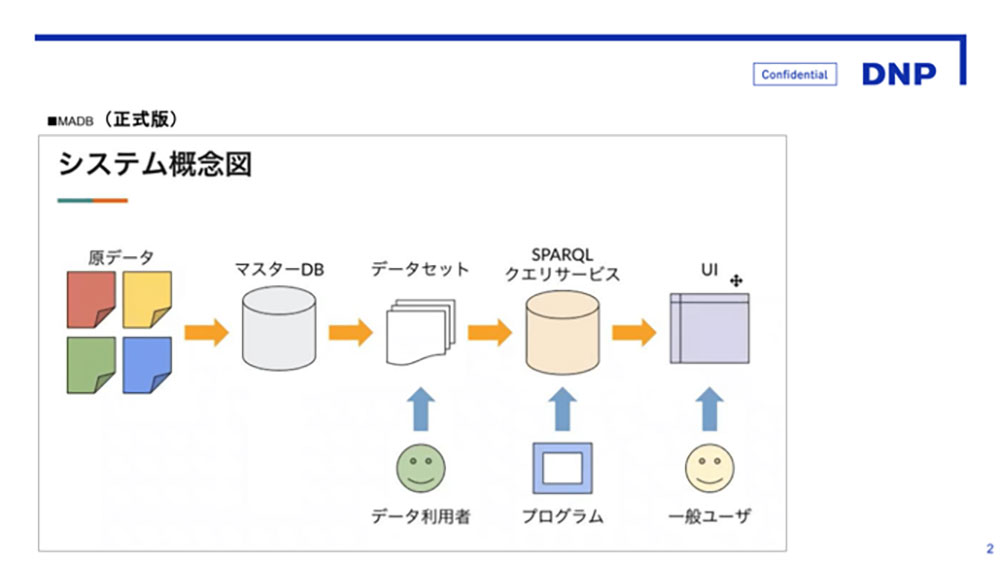
大向 データの粒度を揃え、整えたことでなにができるようになったかというと、データを集計したり、統計的に処理したりできるようになりました。それはMADBにとっては非常に大きなことです。MADBは発足当初から「日本のメディア芸術の全体像を明らかにする」という使命を持っていますが、データベースというと、必要なところだけ引き出して使うようなイメージで、その全体像は捉えにくいですよね。検索機能だけでは、対象の全体像に近づくのはとても難しく、結局自分が知っているものやそれに関連するものしか見えてこない。
三原 例えば「メディア芸術はいつ何作品つくられている?」といった問いに、MADBが答えられるようになったということですね。これはMADB Labでも調査レポートとして公開している情報ですが、マンガについて、国立国会図書館に入っている件数や世の中にある統計資料で挙げられている件数と、MADBのデータ件数を比べると、全然違う。統計資料には計上されていないマンガが、連携機関の所蔵する資料により、古いものをはじめ相当数あるということがMADBを通じて明らかになったのです。
このようにデータの粒度を揃えたことで、ようやく当初の目的に少し近づけたと思っています。
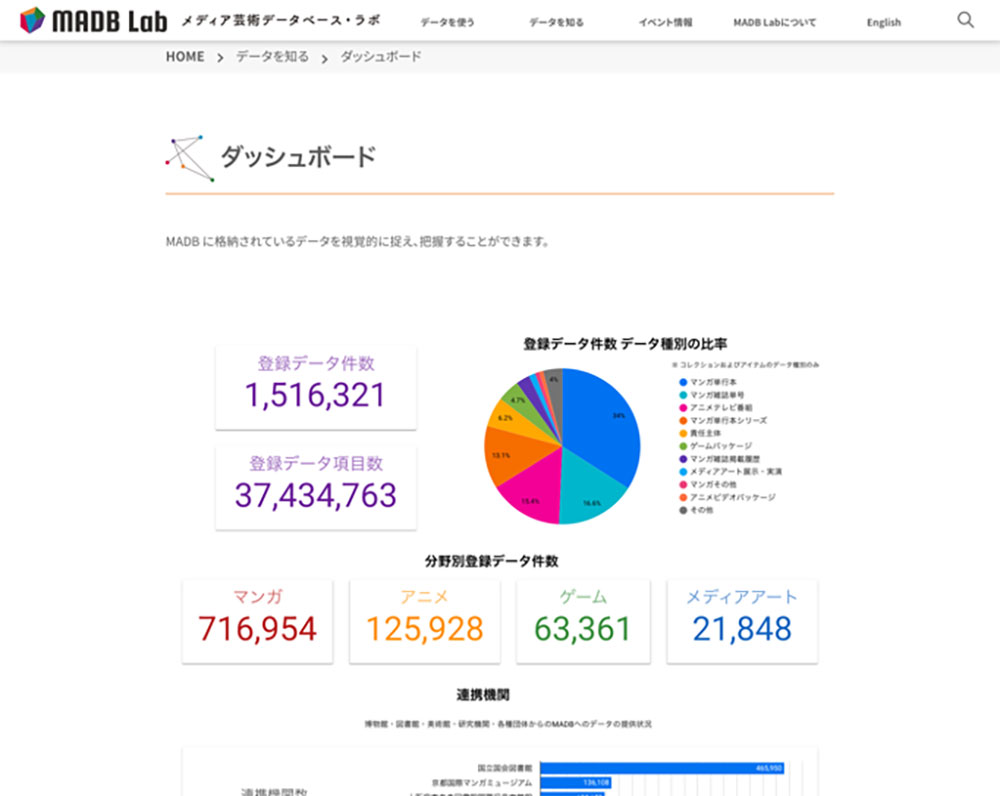
正式版へのリニューアルに際して、MADB Labに「ダッシュボード」というページを追加しました。これはMADBのデータの全体像を、色々な観点で統計的に見ることのできるサマリーです。ページの裏ではSPARQLを使ってデータベースに逐次問い合わせをしていて、その結果を表示しています。つまり、データベースのデータが増えれば、表示される値も自動的に増えます。
大向 ベータ版での取り組みを通じて、システムのあるべき姿やデータのまとめ方が整理され、ようやくエンドユーザーがサービスとして享受できるところまでたどり着いたというところですね。
大向 たどり着いた、と宣言しましたが、ここでなにか具体例を考えてみましょうか。例えば「近年で一番タイトルが長い作品を調べたい」ユーザーはどうしますか。
三原 SPARQLを使えば、おそらくデータは一発で取れます。ただし二つ問題があって、まず一つは、SPARQLの使い方を熟練しているユーザーがまだまだ少ないこと。そのデータを取ってくるクエリを実際に書ける人は多分、日本でまだ数十人ぐらいだと思います。学んで理解すれば誰でも書けるようになりますが、クエリをつくるには一定の専門的知識が必要です。
大向 三原さんや僕はSPARQLを自分の授業で扱っていますが、もっと普及させたいですね。SPARQLクエリサービスと同等の機能を持っているデジタルアーカイブも徐々に増えていますし、SPARQLが使えるとWikipedia(Wikidata1)の情報を効率よく検索できたりもします。
三原 そろそろ『マンガでわかる楽しいSPARQL』をつくりたいですね。もう一つは、例えばテレビアニメの各話のタイトルなどを対象にした場合、1回の放送に複数話が含まれている場合があるのです。ドラえもんやサザエさんを想像してもらうとわかりやすいです。そうすると、1作品という枠に複数話がまとまっていて、タイトルも複数話分入っている可能性があります。本来作品や放送回、各話の単位がきちんと整理されて登録されていることが望ましいのですが、提供されているデータのつくられ方やそもそもの作品の提供のされ方は実に多様なので、現時点ではそうした整備が行き届いていないケースがあります。
こうした場合、取ってきたデータのままでは検証できないので、リストをダウンロードして、表計算ソフトなどを用いてデータを自分で加工したり処理したりする必要があります。そう考えると、SPARQLをさほど駆使できるようにならなくても、データベースからは無理のない範囲で抜き出して、あとは自分で加工して集計するというような想定をした方がいいのかもしれません。
僕は今文学科で授業や研究指導を担当しているのですが、卒業研究で子どもの化粧文化の変遷をテーマにするという学生がいました。「児童向けの少女マンガ誌の付録と特集で、化粧をテーマにしたものを探したい。国立国会図書館で地道に探そうか」などと言っていたので、MADBにある雑誌の目次データを、僕がクエリを書いて検索しました。MADBに登録されている雑誌全てに目次のデータがあるわけではないのですが、学生が探している年代のものはたまたまあったのです。目次と付録のデータを抜いてきて、エクセルで扱えるリストの形にして渡しました。その後、実際に調査に行く手間や費用が省けてだいぶ助かったと言ってもらえました。
大向 正式版としてリリースしたとはいえ、メディア芸術そのものが常に変化する多様なものですから、やればやるほど課題が見えてくる部分もあります。
冒頭の三原さんのお話にもあったように、マンガ分野でも原画、雑誌、単行本、電子書籍、さらにはグッズ展開や、アニメ化、ゲーム化といった広がりをどう捉えつなげていくか。ファンミーティングのようなイベント、つまり「もの」ではなく「こと」がどんどん増えている側面もあります。それらをMADBで捉えるにはどうしたらいいのか……。
三原 おっしゃる通り、コトのデータをちゃんと集めたいですよね。基盤的な仕組みがないので現時点ではほとんどできていないというのが現実です。コトとしてまずあるのは展覧会です。メディア芸術領域を扱う展覧会は今や国内で開催されていない日はないほどに増えていて、地方でも盛んです。どんなイベントだったか、何が展示されて、それらをどこが持っているものなのかという情報は、なかなかコミュニティの外からはアクセスしづらいし残らない。残ることで再演や再展示の可能性が広がったり、新たな企画につながったりするということは明らかなので、捉えていきたいところですね。
ゲームから派生したアイドルユニットのライブ、なんて、どう捉えたらよいのでしょうね。アニメの主題歌を歌う歌手など、作品に紐づく人物は記録可能ですが、そのものを記録する手段は現状ありません。
ただ、MADBだけで解決しなくていいとも思っています。別のところでつくられているデータベースと、こちらのデータベースで、ある人物が同一人物であることを判断できれば、情報のつながりのなかで多様な活動が見えてくるかもしれない。MADBが、たくさんあるなかの一つの重要なパーツを担えたらいいですね。
三原 MADBのどの分野にも言えるのですが、現状のエンドユーザーには研究者やそのジャンルについて詳しいファンが多いので、ユーザーが一番進んでいるというジレンマもあります。「なぜ自分達がアクセスできている情報がMADBでは出てこないのか」と、エンドユーザーからの要求が一番厳しい。データの整合性や未来永劫使えるための妥当性みたいなものを検証するプロセスを経ると、どうしても時間がかかってしまうし、世の中の変化が多様でかつ大量にデータが来るため、キャッチアップできない部分が出てきてしまう。それがMADBの弱点であり続けているので、そこをクリアする方法は常に模索しているところではあります。
大向 新しすぎる動きというのは、それを捉えようというコミュニティもまだなく、データベースに定期的に取り込もうとしてもなかなか難しいですね。コミュニティも含めて常に後から現れてくるものだと思いますし、どうしても追いかけるかたちにならざるを得ない。
三原 新しい動きを追うことも必要ですが、過去から現在まで継続してデータがあることもまた非常に重要です。今国内におけるSPARQLで検索可能なサービスのなかで、リアルタイムの文化・社会現象を扱っているのは、DBpedia2とMADBぐらいしかないのではないでしょうか。カレントデータ(カレント=現在の。その時その時の状況についてのデータ)に対する関心というのはとても高まっているわけですが、過去からのデータが一気通貫していることで、その価値はさらに高まるはずです。まだMADBに存在しない遡及データをさらに充実させるために、今後も連携機関を増やし、また連携済みのデータの更新も行っていきたいところです。
登録済みの情報の精度を上げるにはユーザーの力も必要と考えています。膨大なデータがあり、つくり手が把握できる量には限界があります。データをお持ちの方には、お手元のデータとMADBのデータを突合してMADBの至らないところを指摘したり、穴を埋めたりしていただきたい。使えば使うほどデータが良くなるようなサイクルを実現したいと考えています。データをオープンにしているのはそのためでもあります。
大向 ユーザーや連携機関によるデータの増加や質の向上については、その貢献が明示できるとよさそうですね。本当にたくさんの方々に支えてもらっているサービスなので、積極的に伝えていきたいです。
大向 いま大学でも徐々にデータサイエンスを必修化するような方向になっていますが、その教材としてMADBはとても有用です。同じスキルを学ぶにしても、扱うデータがおもしろかったり、より身近だったりすると分析も楽しくなると思います。MADB Labでは「メディア芸術データベースで学ぶデータサイエンス」というページを設け、教員・学生向けのテキストやデータセットなど、オンライン教材を公開しています。
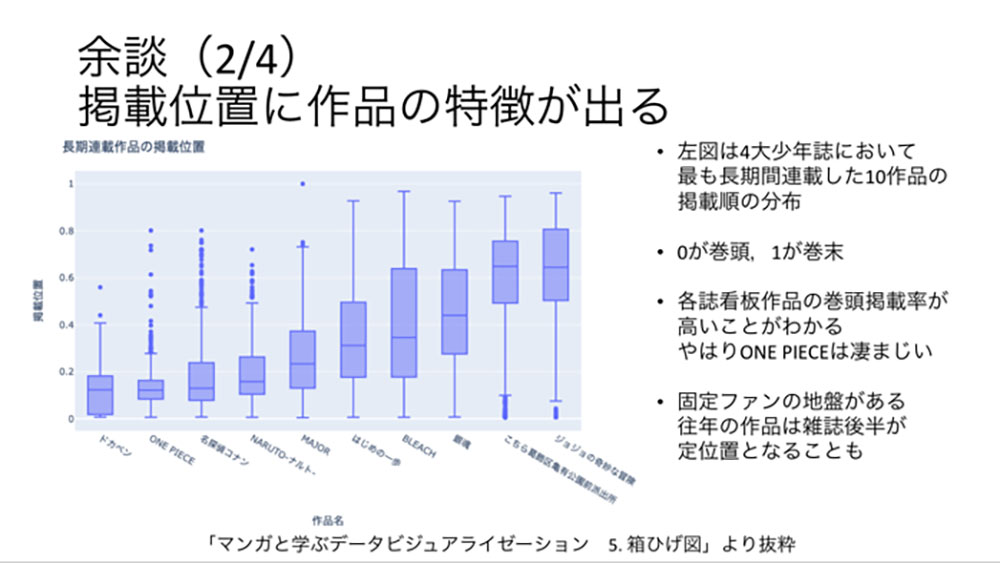
三原 オンライン教材をつくる前段として、2021年からデータベース活用アイディアソンや活用コンテストを実施し、そこで我々関係者が思いもよらなかった活用の事例が生まれました。2022年のコンテストでビジュアルクリエイション部門最優秀事例となった「マンガと学ぶデータサイエンス」は、『週刊少年サンデー』『週刊少年ジャンプ』『週刊少年チャンピオン』『週刊少年マガジン』の四つの週刊少年誌のデータを用いてさまざまなデータビジュアライゼーションを行ったものです。雑誌の目次データを用いて、作品掲載順と作品の人気の関係が可視化されていて、それを見たときには関係者一同騒然となりました。
大向 データベースのつくり手の想像をはるかに超えた情報の使われ方でしたね。整理されたリッチなデータとユーザーの熱意が掛け合わされるとこんなものができるのかと、衝撃を受けました。MADB Labからはコンテスト受賞作をたどれるほか、データの活用事例も掲載しています。活用事例はもっと増やしていきたいですね。
大向 今後は国際発進にも力を入れていきたいところですが、データの連携という点では、すでに我々の預かり知らぬところで国際的な広がりを見せている面もあります。
最初にお話しした、作品に振られた永久不滅のID、それが例えばWikidataのとあるゲーム作品のページに、関連するIDとして掲載されている場合があります。WikidataのページからMADBの同じ作品のデータに飛ぶことができるわけですが、海外のゲーム研究者のコミュニティがWikipediaとMADBとをつなげようと、Wikidata側にこちらのIDを登録してくれたようです。ほかの分野でももしかしたら誰かがポチポチと登録してくれているかもしれません。IDの存在やその意義については今後もアピールしていきたいところです。
三原 先ほどお話ししたような国内での連携と同様の話が、海外でもないわけではありません。ただ、海外の網羅的なデータベースには現在のMADBでは対象にしていない日本以外で製作された作品のデータが含まれることも多いです。そうした場合、データベース全体ではなく部分的な連携になり、より緻密さが求められます。
あるいは、海外でもデータベース全体で連携できそうなのは、日本文化の研究者など、日本に関心がある個人がつくっているものです。マッチしそうなところに働きかけて、情報提供していく必要があります。
大向 海外との連携も、結局のところ人とのつながりが不可欠ですね。データベース側で国際発進をより能動的に進めようとすると多言語化の問題などが出てきます。多言語を人力で入力することはもはや考えにくいですが、完璧な多言語データを目指さずとも、AIなどを駆使して海外ユーザーのアクセスをサポートするようなことは可能だと思っています。現時点でも、ナビゲーションは4カ国語に対応しています。
三原 今メディア芸術はコロナ禍を経て極端にボーダレスに提供されるようになっていて、日本で公開されればすぐに海外でも見られるなど、数年前にはあったラグがほぼなくなっている。日本だけ捉えていていいのかという話が、急速に突きつけられている状況でもあります。どういうふうにデータを集めればいいのか。日本のアニメの配信をしている映像配信サービスや、マンガの発信をしている事業者などとの連携は、さらに次のステップになるとは思いますが、必要なことであり、価値のあることだと認識しています。
大向 2023年4月にMADBの管理が文化庁から国立アートリサーチセンターへ移り、個人的には美術館的なものの捉え方から学べるものは多いのではないかと期待しています。私のバックグラウンドに近い図書館は複製されたものを扱う場所です。対して美術館は一点ものを扱う場所です。捉え方の難しいものをどう考えていくのか、さまざまな視点から学び、一緒に考えていくきっかけになればと思っています。
三原 そうですね。大向さんもおっしゃったように、やはり図書館はものと情報を提供するという意識があるのに対して、美術館はより視野が広い部分があると思います。そこへの期待は大きいです。
メディア芸術というのは、マンガ、アニメ、ゲーム、メディアアートという、それまでは芸術として捉えられていなかったものをちゃんと芸術文化にしましょうという取り組みだったわけですが、今やそれらが芸術文化だということを否定する人は少ないと思います。でも「じゃあなぜ芸術文化なのか」を説明するのは難しい。芸術の価値には評価の蓄積が必要なのではないでしょうか。 これまで整えたベースに、美術的な価値視点を盛り込んだりつなげたりしていけたら、MADBはよりリッチに、メディア芸術の芸術的な評価の蓄積を提供できるのではないかと思います。
脚注
三原 鉄也(みはら・てつや)
筑波大学人文社会系助教。博士(情報学)。大学でのマンガのメタデータ技術の研究の傍ら、マンガ制作のマネジメントも行っている。メディア芸術データベースの関連プロジェクトでは複数の分野や機関、データ源の連携が容易なメタデータモデルの設計や機能開発の助言を担当している。
大向一輝(おおむかい・いっき)
東京大学大学院人文社会系研究科准教授。博士(情報学)。専門はウェブ情報学、人文情報学で、学術情報サービスCiNiiの開発リーダーを約10年間務めた。メディア芸術データベースではサービス全体の「プロデューサー」としてシステムの基本設計やユーザーインターフェイスを主に担当している。
※インタビュー日:2024年2月29日
※URLは2024年3月15日にリンクを確認済み





